 ePub (Kindle)
ePub (Kindle)
 Printable PDF
Printable PDF
Lost confidence


Confidence games
Many prioritization frameworks include a measure of confidence1—how sure we are that we can execute, at more-or-less the predicted estimated effort, resulting in more-or-less the predicted impact. This seems rational; if two projects generate equal value for equal effort, but we’re confident we can execute the first and unsure about the second, we should select the first.
1 Or a measure of risk. Whetherriskis equal to1—confidenceis left to the discretion of the reader.
This is not, however, how confidence scores are used. If it were, the process would look like this:
- Score projects somehow.
- If there’s one clear winner, do it.
- If there’s a tie, pick the one we are more confident in.
That’s not a bad idea. But popular frameworks like RICE include “confidence” in step one:
%22%3E%3Cg%20data-mml-node=%22math%22%3E%3Cg%20data-mml-node=%22mstyle%22%3E%3Cg%20data-mml-node=%22TeXAtom%22%20data-mjx-texclass=%22ORD%22%3E%3Cg%20data-mml-node=%22mtext%22%3E%3Cpath%20data-c=%2253%22%20d=%22M55%20507q0%2083%2057%20140t131%2057h14q85%200%20148-63l21%2031q5%207%2010%2015t10%2013l3%204q1%200%204%200t6%201h4q3%200%209-6V462l-6-6H448q-11%200-13%203t-5%2020Q413%20605%20329%20646q-37%2016-75%2016-53%200-86-36t-33-84q0-34%2017-62t48-45q10-4%2086-23t84-23q57-22%2093-75t37-123q0-81-52-146T301-21Q245-21%20201-4T140%2027L122%2041q-4-5-15-20T87-7%2078-21q-2-1-10-1H64q-3%200-9%206V101q0%20119%201%20121%202%205%2020%205H89q6-6%206-13%200-32%2010-63t34-61%2066-48T305%2024q47%200%2081%2038t34%2093q0%2043-22%2078t-58%2048q-56%2014-74%2019-5%201-27%206t-33%208-32%2011-33%2018-29%2024-27%2035Q55%20451%2055%20507z%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(556,0)%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(1000,0)%22/%3E%3Cpath%20data-c=%2272%22%20d=%22M36%2046H50q39%200%2047%2014v8q0%209%200%2023t1%2031%200%2039%200%2042q0%2031%200%2066t0%2059l-1%2023q-3%2019-14%2025t-45%209H20v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q16%201%2035%202t29%203%2011%201h3V373q39%2068%2097%2068h6q45%200%2066-22t21-46q0-21-13-36t-38-15-37%2016-13%2034q0%209%202%2016t5%2012%203%205q-2%202-23-4-16-8-24-15-47-45-47-179V154q0-13%200-27t0-26%201-20%200-15V61q1-2%203-4t5-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9Q249%203%20140%203%2037%203%2028%200H20V46H36z%22%20transform=%22translate(1500,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(1892,0)%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mo%22%20transform=%22translate(2613.8,0)%22%3E%3Cpath%20data-c=%223D%22%20d=%22M56%20347q0%2013%2014%2020H707q15-8%2015-20%200-11-14-19l-318-1H72q-16%205-16%2020zm0-194q0%2015%2016%2020H708q14-10%2014-20%200-13-15-20H70q-14%207-14%2020z%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mstyle%22%20transform=%22translate(3669.6,0)%22%3E%3Cg%20data-mml-node=%22mfrac%22%3E%3Cg%20data-mml-node=%22mrow%22%20transform=%22translate(220,676)%22%3E%3Cg%20data-mml-node=%22mtext%22%3E%3Cpath%20data-c=%2252%22%20d=%22M130%20622q-7%207-11%209t-16%203-43%203H27v46H202h34%2064q76%200%20117-6t83-29q95-48%20109-131%201-5%201-16%200-33-16-62t-38-47-45-31-39-18l-16-5q3-3%2011-6%2030-16%2049-34t29-44%2014-43%209-56%2010-61q10-48%2024-63t38-15h5q15%200%2029%2016t18%2055q0%2011%204%2014t16%204%2016-2%204-13q0-31-16-63T672-16q-16-6-42-6Q481-16%20458%2090q-2%2011-2%2073t-7%2083q-19%2058-76%2074l-10%202-66%201H231V192l1-131q6-10%2017-12t52-3h33V0H323Q302%203%20181%203%2059%203%2038%200H27V46H60q42%201%2051%203t19%2012V622zM491%20499v10q0%2018-1%2030t-9%2031-19%2031-38%2022-62%2013q-2%200-22%200t-36%201H283q-45%200-49-9-3-4-3-136V360h58q101%200%20145%2018t55%2078q2%2011%202%2043z%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(736,0)%22/%3E%3Cpath%20data-c=%2261%22%20d=%22M137%20305t-22%200-37%2015-15%2039q0%2035%2034%2062t121%2027q73%200%20118-32t60-76q5-14%205-31t1-115V124q0-48%205-66t21-18q15%200%2020%2016t5%2053v36h40V106q-1-40-3-47-9-30-35-47T4e2-6%20353%2012%20329%2054v4l-2-3q-2-3-5-6t-8-9-12-11-15-12T269%206%20247-2%20221-8t-31-3Q130-11%2082%2020T34%20107q0%2021%207%2040t27%2041%2048%2037%2078%2028%20110%2015h14v22q0%2034-6%2050-22%2071-97%2071-18%200-34-1t-25-4-8-3q22-15%2022-44%200-25-16-39zM126%20106q0-31%2024-55t59-25q38%200%2067%2023t39%2060q2%207%203%2066%200%2058-1%2058-8%200-21-1t-45-9-58-20-46-37-21-60z%22%20transform=%22translate(1180,0)%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(1680,0)%22/%3E%3Cpath%20data-c=%2268%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2033%200%2043%201%2050%200%2055%200%2057q0%2037%200%2078t0%2075-1%2060%200%2044%200%2017q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V367q60%2075%20144%2075%20123%200%20135-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(2124,0)%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mo%22%20transform=%22translate(2902.2,0)%22%3E%3Cpath%20data-c=%22D7%22%20d=%22M630%2029q0-20-21-20-5%200-22%2016t-94%2093L389%20222%20284%20117Q178%2013%20175%2011q-4-2-7-2-8%200-14%206t-7%2014q0%207%2014%2022t94%2095L359%20250%20255%20354q-81%2081-94%2095t-14%2022q0%209%206%2014t15%205q5%200%207-1%203-2%20109-106L389%20278%20493%20382q77%2077%2094%2093t22%2016q21%200%2021-20%200-7-10-18t-98-98L418%20250%20522%20145q84-84%2096-97t12-19z%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mtext%22%20transform=%22translate(3902.4,0)%22%3E%3Cpath%20data-c=%2249%22%20d=%22M328%200Q307%203%20180%203T32%200H21V46H43q49%200%2063%203t20%2011q2%203%202%20282%200%20278-2%20281-4%205-8%207t-22%205-53%202H21v46H32q21-3%20148-3t148%203h11V637H317q-49%200-63-3t-20-11q-2-3-2-281%200-279%202-282%204-5%208-7t22-5%2053-2h22V0H328z%22/%3E%3Cpath%20data-c=%226D%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q15%200%2028-2t23-6%2019-8%2015-9%2011-11%209-11%207-11%204-10%203-8l2-5%203%204q3%204%206%208t9%2011%2013%2013%2015%2013%2020%2012%2023%2010%2026%207%2031%203q126%200%20137-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L788%201q-24%201-51%201T699%203Q596%203%20587%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(361,0)%22/%3E%3Cpath%20data-c=%2270%22%20d=%22M36-148H50q39%200%2047%2014v8q0%207%200%2019t0%2030%201%2039T98%206t0%2049%200%2051q0%2034%200%2071t0%2066%200%2053-1%2039%200%2016q-3%2019-14%2025t-45%209H20v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V416l1-26%208%207q59%2044%20138%2044%2081%200%20138-64t58-161q0-101-65-164T310-11q-68%200-120%2044l-8%207V-45-101q0-27%202-33t11-11q21-3%2049-3h16v-46h-8l-24%201q-23%201-50%201t-38%201q-103%200-112-3H20v46H36zM424%20218q0%2074-34%20129t-85%2055q-71%200-123-65V98q40-72%20112-72%2051%200%2090%2054t40%20138z%22%20transform=%22translate(1194,0)%22/%3E%3Cpath%20data-c=%2261%22%20d=%22M137%20305t-22%200-37%2015-15%2039q0%2035%2034%2062t121%2027q73%200%20118-32t60-76q5-14%205-31t1-115V124q0-48%205-66t21-18q15%200%2020%2016t5%2053v36h40V106q-1-40-3-47-9-30-35-47T4e2-6%20353%2012%20329%2054v4l-2-3q-2-3-5-6t-8-9-12-11-15-12T269%206%20247-2%20221-8t-31-3Q130-11%2082%2020T34%20107q0%2021%207%2040t27%2041%2048%2037%2078%2028%20110%2015h14v22q0%2034-6%2050-22%2071-97%2071-18%200-34-1t-25-4-8-3q22-15%2022-44%200-25-16-39zM126%20106q0-31%2024-55t59-25q38%200%2067%2023t39%2060q2%207%203%2066%200%2058-1%2058-8%200-21-1t-45-9-58-20-46-37-21-60z%22%20transform=%22translate(1750,0)%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(2250,0)%22/%3E%3Cpath%20data-c=%2274%22%20d=%22M27%20422q53%204%2082%2056t32%20122v15h40V431H316V385H181V241q1-125%201-141t7-32q14-39%2049-39%2044%200%2054%2071%201%208%201%2046v35h40V146%20134q0-77-42-117-27-27-70-27-34%200-59%2012T124%2033%20105%2068t-7%2032q-1%207-1%20148V385H18v37h9z%22%20transform=%22translate(2694,0)%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mo%22%20transform=%22translate(7207.7,0)%22%3E%3Cpath%20data-c=%22D7%22%20d=%22M630%2029q0-20-21-20-5%200-22%2016t-94%2093L389%20222%20284%20117Q178%2013%20175%2011q-4-2-7-2-8%200-14%206t-7%2014q0%207%2014%2022t94%2095L359%20250%20255%20354q-81%2081-94%2095t-14%2022q0%209%206%2014t15%205q5%200%207-1%203-2%20109-106L389%20278%20493%20382q77%2077%2094%2093t22%2016q21%200%2021-20%200-7-10-18t-98-98L418%20250%20522%20145q84-84%2096-97t12-19z%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mtext%22%20transform=%22translate(8207.9,0)%22%3E%3Cpath%20data-c=%2243%22%20d=%22M56%20342q0%2086%2033%20158t85%20115%20109%2066%20108%2024q3%200%209%200t8-1q91%200%20161-68l13-12%2030%2039q27%2037%2031%2041%201%200%204%200t6%201h4q3%200%209-6V419l-6-6H626q-6%206-7%2017-9%2082-48%20142t-95%2079q-19%207-50%207-104%200-174-70-79-79-79-246%200-121%2038-191%2021-40%2052-67t65-39%2056-16%2044-5q89%200%20143%2069t55%20151q0%207%206%2013h28l6-6V236q-5-103-76-180T403-21Q262-21%20159%2083T56%20342z%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(722,0)%22/%3E%3Cpath%20data-c=%226E%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q114-4%20127-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(1222,0)%22/%3E%3Cpath%20data-c=%2266%22%20d=%22M273%200Q255%203%20146%203%2043%203%2034%200H26V46H42q28%200%2049%203%208%203%2012%2011%201%202%201%20164V385H33v46h71v66l1%2067%202%2010q19%2065%2064%2094t95%2036q1%200%209%200t14%201q41-3%2062-26t21-52q0-23-14-37t-37-14-37%2014-14%2037q0%2020%2018%2040h-4q-4%201-11%201-28%200-50-21t-34-55q-6-20-7-95V431H293V385H185V225q0-162%201-164t3-4%205-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9z%22%20transform=%22translate(1778,0)%22/%3E%3Cpath%20data-c=%2269%22%20d=%22M69%20609q0%2028%2018%2044t44%2016q23-2%2040-17t17-43q0-30-17-45t-42-15-42%2015-18%2045zM247%200Q232%203%20143%203q-11%200-37%200T56%201L34%200H26V46H42q28%200%2049%203%209%204%2011%2011t2%2042V205v88q0%2052-2%2066T88%20378q-14%207-47%207H30v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q17%201%2036%202t29%203%2011%201h3V62q5-10%2012-12t35-4h23V0h-8z%22%20transform=%22translate(2084,0)%22/%3E%3Cpath%20data-c=%2264%22%20d=%22M376%20495q0%2016%200%2040t1%2033q0%2045-10%2056t-51%2013H298v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V390q0-306%201-309%203-20%2014-26t45-9h18V0q-2%200-76-5t-79-6h-7V44l-8-7Q307-11%20235-11%20158-11%2096%2050T34%20215q0%201e2%2063%20163t147%2064q75%200%20132-49V495zm-3-153q-45%2063-113%2063-49%200-87-36-27-28-34-64t-8-94q0-56%207-91t35-61q30-33%2078-33%2071%200%20122%2077V342z%22%20transform=%22translate(2362,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(2918,0)%22/%3E%3Cpath%20data-c=%226E%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q114-4%20127-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(3362,0)%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(3918,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(4362,0)%22/%3E%3C/g%3E%3C/g%3E%3Cg%20data-mml-node=%22mtext%22%20transform=%22translate(5439.9,-686)%22%3E%3Cpath%20data-c=%2245%22%20d=%22M128%20619q-7%207-11%209t-16%203-43%203H25v46H597v-4q2-6%2014-116t14-116v-4H585v4q-1%203-3%2021-4%2035-12%2061t-17%2045-25%2030-30%2018-41%2010-46%204-58%201q-87%200-102-1t-18-11v-1q-1-2-1-124V376h54q73%202%2091%209%2036%2016%2039%2084%200%202%200%204v20h40V213H416v20q-1%2035-8%2055t-25%2029-34%2011-52%202q-7%200-11%200H232V196%20114q0-57%205-62%206-5%2052-5h51%2051q37%200%2061%203t53%2012%2047%2030%2032%2054q10%2026%2015%2054t8%2047%205%2023v3h40v-3q-1-3-20-133T610%203V0H25V46H58q42%201%2051%203t19%2012V619z%22/%3E%3Cpath%20data-c=%2266%22%20d=%22M273%200Q255%203%20146%203%2043%203%2034%200H26V46H42q28%200%2049%203%208%203%2012%2011%201%202%201%20164V385H33v46h71v66l1%2067%202%2010q19%2065%2064%2094t95%2036q1%200%209%200t14%201q41-3%2062-26t21-52q0-23-14-37t-37-14-37%2014-14%2037q0%2020%2018%2040h-4q-4%201-11%201-28%200-50-21t-34-55q-6-20-7-95V431H293V385H185V225q0-162%201-164t3-4%205-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9z%22%20transform=%22translate(681,0)%22/%3E%3Cpath%20data-c=%2266%22%20d=%22M273%200Q255%203%20146%203%2043%203%2034%200H26V46H42q28%200%2049%203%208%203%2012%2011%201%202%201%20164V385H33v46h71v66l1%2067%202%2010q19%2065%2064%2094t95%2036q1%200%209%200t14%201q41-3%2062-26t21-52q0-23-14-37t-37-14-37%2014-14%2037q0%2020%2018%2040h-4q-4%201-11%201-28%200-50-21t-34-55q-6-20-7-95V431H293V385H185V225q0-162%201-164t3-4%205-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9z%22%20transform=%22translate(987,0)%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(1293,0)%22/%3E%3Cpath%20data-c=%2272%22%20d=%22M36%2046H50q39%200%2047%2014v8q0%209%200%2023t1%2031%200%2039%200%2042q0%2031%200%2066t0%2059l-1%2023q-3%2019-14%2025t-45%209H20v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q16%201%2035%202t29%203%2011%201h3V373q39%2068%2097%2068h6q45%200%2066-22t21-46q0-21-13-36t-38-15-37%2016-13%2034q0%209%202%2016t5%2012%203%205q-2%202-23-4-16-8-24-15-47-45-47-179V154q0-13%200-27t0-26%201-20%200-15V61q1-2%203-4t5-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9Q249%203%20140%203%2037%203%2028%200H20V46H36z%22%20transform=%22translate(1793,0)%22/%3E%3Cpath%20data-c=%2274%22%20d=%22M27%20422q53%204%2082%2056t32%20122v15h40V431H316V385H181V241q1-125%201-141t7-32q14-39%2049-39%2044%200%2054%2071%201%208%201%2046v35h40V146%20134q0-77-42-117-27-27-70-27-34%200-59%2012T124%2033%20105%2068t-7%2032q-1%207-1%20148V385H18v37h9z%22%20transform=%22translate(2185,0)%22/%3E%3C/g%3E%3Crect%20width=%2213213.9%22%20height=%2260%22%20x=%22120%22%20y=%22220%22/%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
Or RPS:
%22%3E%3Cg%20data-mml-node=%22math%22%3E%3Cg%20data-mml-node=%22mstyle%22%3E%3Cg%20data-mml-node=%22TeXAtom%22%20data-mjx-texclass=%22ORD%22%3E%3Cg%20data-mml-node=%22mtext%22%3E%3Cpath%20data-c=%2253%22%20d=%22M55%20507q0%2083%2057%20140t131%2057h14q85%200%20148-63l21%2031q5%207%2010%2015t10%2013l3%204q1%200%204%200t6%201h4q3%200%209-6V462l-6-6H448q-11%200-13%203t-5%2020Q413%20605%20329%20646q-37%2016-75%2016-53%200-86-36t-33-84q0-34%2017-62t48-45q10-4%2086-23t84-23q57-22%2093-75t37-123q0-81-52-146T301-21Q245-21%20201-4T140%2027L122%2041q-4-5-15-20T87-7%2078-21q-2-1-10-1H64q-3%200-9%206V101q0%20119%201%20121%202%205%2020%205H89q6-6%206-13%200-32%2010-63t34-61%2066-48T305%2024q47%200%2081%2038t34%2093q0%2043-22%2078t-58%2048q-56%2014-74%2019-5%201-27%206t-33%208-32%2011-33%2018-29%2024-27%2035Q55%20451%2055%20507z%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(556,0)%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(1000,0)%22/%3E%3Cpath%20data-c=%2272%22%20d=%22M36%2046H50q39%200%2047%2014v8q0%209%200%2023t1%2031%200%2039%200%2042q0%2031%200%2066t0%2059l-1%2023q-3%2019-14%2025t-45%209H20v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q16%201%2035%202t29%203%2011%201h3V373q39%2068%2097%2068h6q45%200%2066-22t21-46q0-21-13-36t-38-15-37%2016-13%2034q0%209%202%2016t5%2012%203%205q-2%202-23-4-16-8-24-15-47-45-47-179V154q0-13%200-27t0-26%201-20%200-15V61q1-2%203-4t5-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9Q249%203%20140%203%2037%203%2028%200H20V46H36z%22%20transform=%22translate(1500,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(1892,0)%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mo%22%20transform=%22translate(2613.8,0)%22%3E%3Cpath%20data-c=%223D%22%20d=%22M56%20347q0%2013%2014%2020H707q15-8%2015-20%200-11-14-19l-318-1H72q-16%205-16%2020zm0-194q0%2015%2016%2020H708q14-10%2014-20%200-13-15-20H70q-14%207-14%2020z%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mtext%22%20transform=%22translate(3669.6,0)%22%3E%3Cpath%20data-c=%2252%22%20d=%22M130%20622q-7%207-11%209t-16%203-43%203H27v46H202h34%2064q76%200%20117-6t83-29q95-48%20109-131%201-5%201-16%200-33-16-62t-38-47-45-31-39-18l-16-5q3-3%2011-6%2030-16%2049-34t29-44%2014-43%209-56%2010-61q10-48%2024-63t38-15h5q15%200%2029%2016t18%2055q0%2011%204%2014t16%204%2016-2%204-13q0-31-16-63T672-16q-16-6-42-6Q481-16%20458%2090q-2%2011-2%2073t-7%2083q-19%2058-76%2074l-10%202-66%201H231V192l1-131q6-10%2017-12t52-3h33V0H323Q302%203%20181%203%2059%203%2038%200H27V46H60q42%201%2051%203t19%2012V622zM491%20499v10q0%2018-1%2030t-9%2031-19%2031-38%2022-62%2013q-2%200-22%200t-36%201H283q-45%200-49-9-3-4-3-136V360h58q101%200%20145%2018t55%2078q2%2011%202%2043z%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(736,0)%22/%3E%3Cpath%20data-c=%2261%22%20d=%22M137%20305t-22%200-37%2015-15%2039q0%2035%2034%2062t121%2027q73%200%20118-32t60-76q5-14%205-31t1-115V124q0-48%205-66t21-18q15%200%2020%2016t5%2053v36h40V106q-1-40-3-47-9-30-35-47T4e2-6%20353%2012%20329%2054v4l-2-3q-2-3-5-6t-8-9-12-11-15-12T269%206%20247-2%20221-8t-31-3Q130-11%2082%2020T34%20107q0%2021%207%2040t27%2041%2048%2037%2078%2028%20110%2015h14v22q0%2034-6%2050-22%2071-97%2071-18%200-34-1t-25-4-8-3q22-15%2022-44%200-25-16-39zM126%20106q0-31%2024-55t59-25q38%200%2067%2023t39%2060q2%207%203%2066%200%2058-1%2058-8%200-21-1t-45-9-58-20-46-37-21-60z%22%20transform=%22translate(1180,0)%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(1680,0)%22/%3E%3Cpath%20data-c=%2268%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2033%200%2043%201%2050%200%2055%200%2057q0%2037%200%2078t0%2075-1%2060%200%2044%200%2017q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V367q60%2075%20144%2075%20123%200%20135-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(2124,0)%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mo%22%20transform=%22translate(6571.8,0)%22%3E%3Cpath%20data-c=%22D7%22%20d=%22M630%2029q0-20-21-20-5%200-22%2016t-94%2093L389%20222%20284%20117Q178%2013%20175%2011q-4-2-7-2-8%200-14%206t-7%2014q0%207%2014%2022t94%2095L359%20250%20255%20354q-81%2081-94%2095t-14%2022q0%209%206%2014t15%205q5%200%207-1%203-2%20109-106L389%20278%20493%20382q77%2077%2094%2093t22%2016q21%200%2021-20%200-7-10-18t-98-98L418%20250%20522%20145q84-84%2096-97t12-19z%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mtext%22%20transform=%22translate(7572,0)%22%3E%3Cpath%20data-c=%2250%22%20d=%22M130%20622q-7%207-11%209t-16%203-43%203H27v46H214q23%200%2062%200t55%201q88%200%20140-13t96-55q57-53%2057-127%200-68-51-117T451%20307q-22-5-123-6H234V181q0-119%203-123%208-11%2067-12h33V0H326Q305%203%20182%203%2047%203%2038%200H27V46H60q42%201%2051%203t19%2012V622zM507%20488q0%2026-1%2040t-6%2036-17%2033-33%2023-53%2015q-12%202-90%202H286q-49%200-52-9-3-4-3-145V342h71%2037q51%200%2084%207t58%2033q26%2029%2026%20106z%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(681,0)%22/%3E%3Cpath%20data-c=%2274%22%20d=%22M27%20422q53%204%2082%2056t32%20122v15h40V431H316V385H181V241q1-125%201-141t7-32q14-39%2049-39%2044%200%2054%2071%201%208%201%2046v35h40V146%20134q0-77-42-117-27-27-70-27-34%200-59%2012T124%2033%20105%2068t-7%2032q-1%207-1%20148V385H18v37h9z%22%20transform=%22translate(1181,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(1570,0)%22/%3E%3Cpath%20data-c=%226E%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q114-4%20127-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(2014,0)%22/%3E%3Cpath%20data-c=%2274%22%20d=%22M27%20422q53%204%2082%2056t32%20122v15h40V431H316V385H181V241q1-125%201-141t7-32q14-39%2049-39%2044%200%2054%2071%201%208%201%2046v35h40V146%20134q0-77-42-117-27-27-70-27-34%200-59%2012T124%2033%20105%2068t-7%2032q-1%207-1%20148V385H18v37h9z%22%20transform=%22translate(2570,0)%22/%3E%3Cpath%20data-c=%2269%22%20d=%22M69%20609q0%2028%2018%2044t44%2016q23-2%2040-17t17-43q0-30-17-45t-42-15-42%2015-18%2045zM247%200Q232%203%20143%203q-11%200-37%200T56%201L34%200H26V46H42q28%200%2049%203%209%204%2011%2011t2%2042V205v88q0%2052-2%2066T88%20378q-14%207-47%207H30v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q17%201%2036%202t29%203%2011%201h3V62q5-10%2012-12t35-4h23V0h-8z%22%20transform=%22translate(2959,0)%22/%3E%3Cpath%20data-c=%2261%22%20d=%22M137%20305t-22%200-37%2015-15%2039q0%2035%2034%2062t121%2027q73%200%20118-32t60-76q5-14%205-31t1-115V124q0-48%205-66t21-18q15%200%2020%2016t5%2053v36h40V106q-1-40-3-47-9-30-35-47T4e2-6%20353%2012%20329%2054v4l-2-3q-2-3-5-6t-8-9-12-11-15-12T269%206%20247-2%20221-8t-31-3Q130-11%2082%2020T34%20107q0%2021%207%2040t27%2041%2048%2037%2078%2028%20110%2015h14v22q0%2034-6%2050-22%2071-97%2071-18%200-34-1t-25-4-8-3q22-15%2022-44%200-25-16-39zM126%20106q0-31%2024-55t59-25q38%200%2067%2023t39%2060q2%207%203%2066%200%2058-1%2058-8%200-21-1t-45-9-58-20-46-37-21-60z%22%20transform=%22translate(3237,0)%22/%3E%3Cpath%20data-c=%226C%22%20d=%22M42%2046H56q39%200%2047%2014v8q0%209%200%2023t0%2033%201%2043%200%2050%200%2055%200%2057q0%2037%200%2078t0%2075%200%2060-1%2044%200%2017q-3%2019-14%2025t-45%209H26v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V379q0-317%201-319%204-8%2012-11%2021-3%2049-3h16V0h-8L232%201q-23%201-49%201T145%203%20107%203%2057%201L34%200H26V46H42z%22%20transform=%22translate(3737,0)%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mo%22%20transform=%22translate(11809.2,0)%22%3E%3Cpath%20data-c=%22D7%22%20d=%22M630%2029q0-20-21-20-5%200-22%2016t-94%2093L389%20222%20284%20117Q178%2013%20175%2011q-4-2-7-2-8%200-14%206t-7%2014q0%207%2014%2022t94%2095L359%20250%20255%20354q-81%2081-94%2095t-14%2022q0%209%206%2014t15%205q5%200%207-1%203-2%20109-106L389%20278%20493%20382q77%2077%2094%2093t22%2016q21%200%2021-20%200-7-10-18t-98-98L418%20250%20522%20145q84-84%2096-97t12-19z%22/%3E%3C/g%3E%3Cg%20data-mml-node=%22mtext%22%20transform=%22translate(12809.4,0)%22%3E%3Cpath%20data-c=%2253%22%20d=%22M55%20507q0%2083%2057%20140t131%2057h14q85%200%20148-63l21%2031q5%207%2010%2015t10%2013l3%204q1%200%204%200t6%201h4q3%200%209-6V462l-6-6H448q-11%200-13%203t-5%2020Q413%20605%20329%20646q-37%2016-75%2016-53%200-86-36t-33-84q0-34%2017-62t48-45q10-4%2086-23t84-23q57-22%2093-75t37-123q0-81-52-146T301-21Q245-21%20201-4T140%2027L122%2041q-4-5-15-20T87-7%2078-21q-2-1-10-1H64q-3%200-9%206V101q0%20119%201%20121%202%205%2020%205H89q6-6%206-13%200-32%2010-63t34-61%2066-48T305%2024q47%200%2081%2038t34%2093q0%2043-22%2078t-58%2048q-56%2014-74%2019-5%201-27%206t-33%208-32%2011-33%2018-29%2024-27%2035Q55%20451%2055%20507z%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(556,0)%22/%3E%3Cpath%20data-c=%226C%22%20d=%22M42%2046H56q39%200%2047%2014v8q0%209%200%2023t0%2033%201%2043%200%2050%200%2055%200%2057q0%2037%200%2078t0%2075%200%2060-1%2044%200%2017q-3%2019-14%2025t-45%209H26v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V379q0-317%201-319%204-8%2012-11%2021-3%2049-3h16V0h-8L232%201q-23%201-49%201T145%203%20107%203%2057%201L34%200H26V46H42z%22%20transform=%22translate(1056,0)%22/%3E%3Cpath%20data-c=%2275%22%20d=%22M383%2058Q327-10%20256-10h-7Q124-10%20105%2089q-1%207-2%20137-1%20109-1%20122t-6%2021q-10%2016-60%2016H25v23q0%2023%202%2023l11%201q10%201%2029%202t38%202q17%201%2037%202t30%203%2012%201h3V261q1-184%203-197%203-15%2014-24%2020-14%2060-14%2026%200%2047%209t32%2023%2020%2032%2012%2030%204%2024q0%201%200%2017t1%2040%200%2047v67q0%2046-10%2057t-50%2013H302v46q2%200%2076%205t79%206h7V264q0-180%201-183%203-20%2014-26t45-9h18V0q-2%200-75-5t-77-6h-7V58z%22%20transform=%22translate(1334,0)%22/%3E%3Cpath%20data-c=%2274%22%20d=%22M27%20422q53%204%2082%2056t32%20122v15h40V431H316V385H181V241q1-125%201-141t7-32q14-39%2049-39%2044%200%2054%2071%201%208%201%2046v35h40V146%20134q0-77-42-117-27-27-70-27-34%200-59%2012T124%2033%20105%2068t-7%2032q-1%207-1%20148V385H18v37h9z%22%20transform=%22translate(1890,0)%22/%3E%3Cpath%20data-c=%2269%22%20d=%22M69%20609q0%2028%2018%2044t44%2016q23-2%2040-17t17-43q0-30-17-45t-42-15-42%2015-18%2045zM247%200Q232%203%20143%203q-11%200-37%200T56%201L34%200H26V46H42q28%200%2049%203%209%204%2011%2011t2%2042V205v88q0%2052-2%2066T88%20378q-14%207-47%207H30v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q17%201%2036%202t29%203%2011%201h3V62q5-10%2012-12t35-4h23V0h-8z%22%20transform=%22translate(2279,0)%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(2557,0)%22/%3E%3Cpath%20data-c=%226E%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q114-4%20127-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(3057,0)%22/%3E%3Cpath%20data-c=%2220%22%20d=%22%22%20transform=%22translate(3613,0)%22/%3E%3Cpath%20data-c=%2243%22%20d=%22M56%20342q0%2086%2033%20158t85%20115%20109%2066%20108%2024q3%200%209%200t8-1q91%200%20161-68l13-12%2030%2039q27%2037%2031%2041%201%200%204%200t6%201h4q3%200%209-6V419l-6-6H626q-6%206-7%2017-9%2082-48%20142t-95%2079q-19%207-50%207-104%200-174-70-79-79-79-246%200-121%2038-191%2021-40%2052-67t65-39%2056-16%2044-5q89%200%20143%2069t55%20151q0%207%206%2013h28l6-6V236q-5-103-76-180T403-21Q262-21%20159%2083T56%20342z%22%20transform=%22translate(3863,0)%22/%3E%3Cpath%20data-c=%226F%22%20d=%22M28%20214q0%2095%2065%20164t157%2070q90%200%20155-68t66-165q0-95-64-160T250-10Q153-10%2091%2057T28%20214zM250%2030q122%200%20122%20163v32%2025q0%2022-1%2038t-7%2038-16%2036-31%2028-49%2020q-5%201-16%201-30%200-57-12-43-22-56-61t-13-92V226q0-96%2019-135%2032-61%20105-61z%22%20transform=%22translate(4585,0)%22/%3E%3Cpath%20data-c=%226E%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q114-4%20127-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(5085,0)%22/%3E%3Cpath%20data-c=%2266%22%20d=%22M273%200Q255%203%20146%203%2043%203%2034%200H26V46H42q28%200%2049%203%208%203%2012%2011%201%202%201%20164V385H33v46h71v66l1%2067%202%2010q19%2065%2064%2094t95%2036q1%200%209%200t14%201q41-3%2062-26t21-52q0-23-14-37t-37-14-37%2014-14%2037q0%2020%2018%2040h-4q-4%201-11%201-28%200-50-21t-34-55q-6-20-7-95V431H293V385H185V225q0-162%201-164t3-4%205-3%205-3%207-2%207-1%209-1%209%200%2010-1%2010%200h31V0h-9z%22%20transform=%22translate(5641,0)%22/%3E%3Cpath%20data-c=%2269%22%20d=%22M69%20609q0%2028%2018%2044t44%2016q23-2%2040-17t17-43q0-30-17-45t-42-15-42%2015-18%2045zM247%200Q232%203%20143%203q-11%200-37%200T56%201L34%200H26V46H42q28%200%2049%203%209%204%2011%2011t2%2042V205v88q0%2052-2%2066T88%20378q-14%207-47%207H30v23q0%2023%202%2023l10%201q10%201%2028%202t36%202q17%201%2036%202t29%203%2011%201h3V62q5-10%2012-12t35-4h23V0h-8z%22%20transform=%22translate(5947,0)%22/%3E%3Cpath%20data-c=%2264%22%20d=%22M376%20495q0%2016%200%2040t1%2033q0%2045-10%2056t-51%2013H298v23q0%2023%202%2023l10%201q10%201%2029%202t37%202q17%201%2037%202t30%203%2011%201h3V390q0-306%201-309%203-20%2014-26t45-9h18V0q-2%200-76-5t-79-6h-7V44l-8-7Q307-11%20235-11%20158-11%2096%2050T34%20215q0%201e2%2063%20163t147%2064q75%200%20132-49V495zm-3-153q-45%2063-113%2063-49%200-87-36-27-28-34-64t-8-94q0-56%207-91t35-61q30-33%2078-33%2071%200%20122%2077V342z%22%20transform=%22translate(6225,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(6781,0)%22/%3E%3Cpath%20data-c=%226E%22%20d=%22M41%2046H55q39%200%2047%2014v8q0%209%200%2023t0%2031%201%2039%200%2042q0%2031%200%2066t-1%2059v23q-3%2019-14%2025t-45%209H25v23q0%2023%202%2023l10%201q10%201%2028%202t37%202q17%201%2036%202t29%203%2011%201h3V402q0-38%201-38t5%205%2012%2015%2019%2018%2029%2019%2038%2016%2051%205q114-4%20127-113%201-7%201-139V104q0-38%202-45t11-10q21-3%2049-3h16V0h-8L510%201q-23%201-50%201T422%203Q319%203%20310%200h-8V46h16q61%200%2061%2016%201%202%201%20138-1%20135-2%20143-6%2028-20%2042t-24%2017-26%202q-45%200-79-34-27-27-34-55t-8-83V168%20108q0-30%201-40t3-13%209-6q21-3%2049-3h16V0h-8L234%201q-24%201-51%201T145%203Q42%203%2033%200H25V46H41z%22%20transform=%22translate(7225,0)%22/%3E%3Cpath%20data-c=%2263%22%20d=%22M370%20305t-21%200-36%2015-16%2038q0%2023%2015%2038%205%205%205%206t-10%202q-26%204-49%204-49%200-80-32-47-47-47-157%200-82%2031-129%2041-61%20110-61%2041%200%2066%2026t36%2062q2%208%205%2010t16%202h14q6-6%206-9%200-4-4-16T395%2071%20366%2033%20318%202%20249-11Q163-11%2099%2053T34%20214q0%20104%2065%20169t151%2065%20120-27%2034-64q0-23-17-37z%22%20transform=%22translate(7781,0)%22/%3E%3Cpath%20data-c=%2265%22%20d=%22M28%20218q0%2055%2020%201e2t50%2073%2065%2042%2066%2015q53%200%2091-18t58-50%2028-64%209-71q0-7-7-14H126V216Q126%2068%20226%2036q20-6%2044-6%2042%200%2072%2032%2017%2017%2027%2042l10%2024q3%203%2016%203h3q17%200%2017-10%200-4-3-13-19-55-63-87T250-11Q155-11%2092%2058T28%20218zm305%2057q-11%20128-95%20136h-2q-8%200-16-1t-25-8-29-21-23-41-16-66v-7H333v8z%22%20transform=%22translate(8225,0)%22/%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
Which means, for example, the following two scenarios are deemed equally strong:
- A small incremental feature, that we’re sure we can execute.
- A large feature, with large impact, that carries some risk.
This equality is false. Especially when you remember that small projects almost always carry higher confidence, and rightly so.2 But that systematically skews the prioritization away from delivering as much value as possible—the opposite of what a prioritization framework ought to do.
2 If you disagree, consider that the entire motivation of the Agile movement was that we should always have low confidence that large projects will be successful, despite our best techniques of planning, analysis, and estimation. And consider this theory of Rocks, Pebbles, and Sand.
I don’t believe your confidence score anyway. First, because it’s ill-defined. What does “30%” mean? What it should mean, is you track your confidence scores and measure how accurate they were after the fact, and determine how good you are at it with mathematical precision. But you don’t do that, do you? And if you only ship a few major features per year, you don’t have enough data to know.
Second, I don’t believe you because we all know that projects are nearly always late, and often have less impact, less quickly, than we wanted. No matter how confident we were. Indeed, everything we choose to do, we have at least “pretty good confidence in,” or we wouldn’t do it at all! So what weight should we place in “confidence?”
Hofstadter’s Law
It always takes longer than you expect, even when you take Hofstadter’s Law into account.
To prove this, find any experienced Product Manager and ask: “Can you recall a feature you were certain would be well-received, but wasn’t?” Perhaps they had evidence from customer conversations, explicit requests, or purchase commitments—yet after building it, almost no one used it, including those who promised they would. Their eyes will roll as they share multiple stories. This doesn’t make them a bad PM. Everyone who has built products, regardless of skill, has these experiences. The best PMs have techniques to mitigate this problem,3 but none will claim they can eliminate it entirely.
3 Some techniques to improve prediction include asking customers to describe exactly how they would use a feature in their normal workflow. Often people genuinely think they would use something, but when forced to walk through it step-by-step, they realize, “Oh wait, this would require me to rewrite this code, we probably wouldn’t do that.” Or, “I’d need to export it into another system—actually, never mind.”
Similarly, ask content creators about their most successful work. Often it’s something they hastily produced—a trivial piece they almost didn’t publish because it seemed uninsightful or trite—yet it generated more views and engagement than anything else that year. Conversely, pieces they spent dozens of hours crafting, work they’re genuinely proud of and consider their best, generate minimal interest:

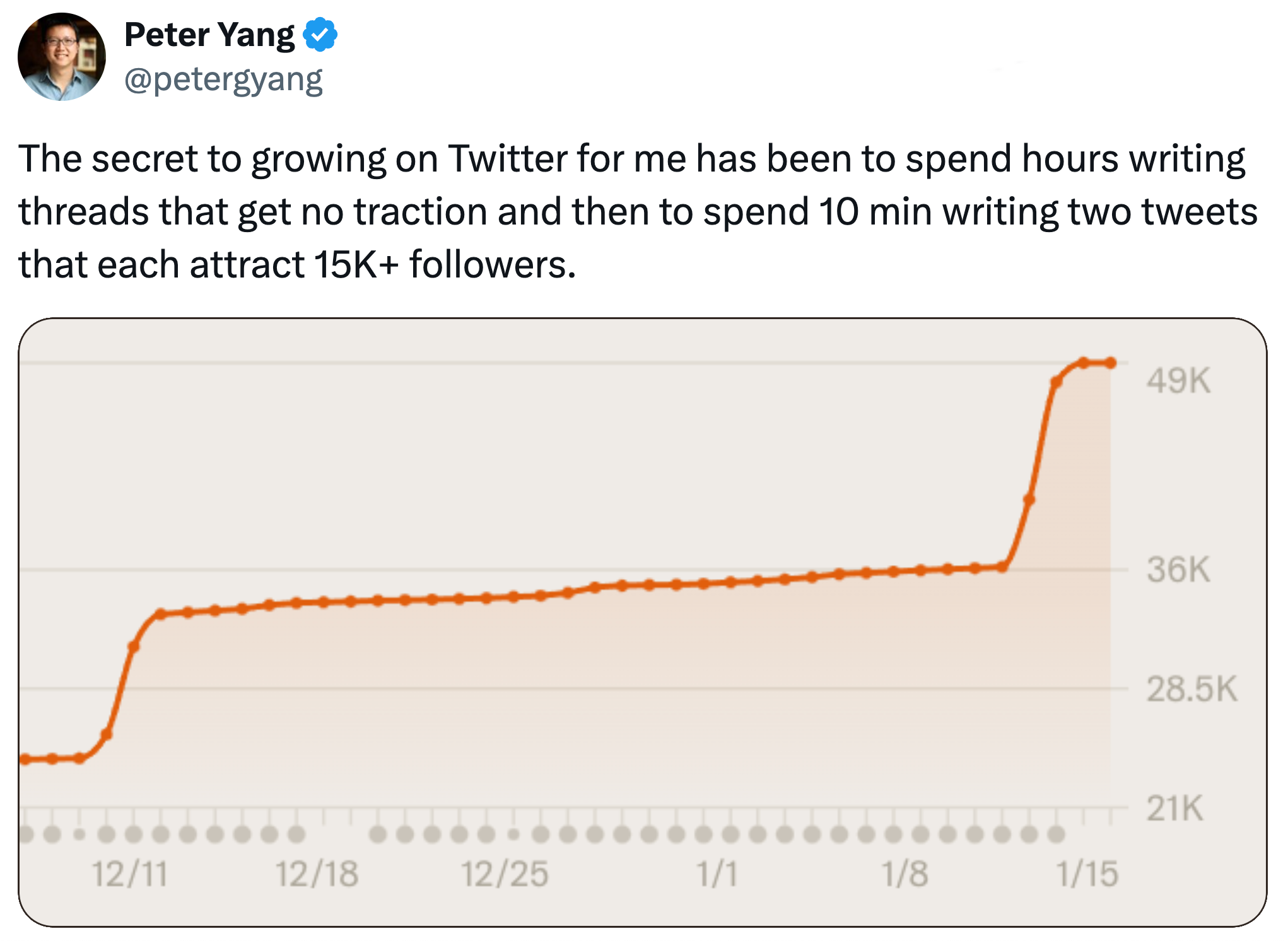
Figure 1
We can summarize the relationship between our confidence and actual results in a handy two-by-two table:
| Was confident | Was not confident | |
| They loved it | Lots of things | Lots of things |
| Nobody cared | Lots of things | Lots of things |
So, if “confidence” is too nebulous to define, and we shouldn’t trust ourselves with it anyway, what should we do?
What to use in place of confidence and risk
The answer lies in the realm of uncertainty, rather than of probability.
Probability presumes you know the underlying distribution, enabling mathematical predictions about future events. You can predict that flipping a fair coin 100 times is highly likely to result in between 40 and 60 heads, because you know the underlying distribution. If predicting whether a feature will create defensible differentiation were like coin-flipping, you could use probabilities.4
Almost nothing in a startup is like that. Outcomes cannot be assigned meaningful probabilities because things like startup success, strategy, and features are unprecedented, or too complex to model accurately, or we have no precision on the input variables. This is the domain of uncertainty.5
4 If you’re tempted to claim that Bayesian methods could still work, remember that you need numeric priors and conditional probabilities, both of which we established above are unknowable and ill-defined.
5 Formally called “Knightian Uncertainty” after economist Frank Knight in his 1921 work “Risk, Uncertainty, and Profit.”
In this domain, we ask: What actions are wise regardless of the probability distribution?
I’ve previously written about embracing uncertainty in overall product strategy. Below, I’ll address a more specific question: How should we prioritize individual items in an uncertain world?
Here are some techniques.
True always
What is always true under any circumstance? This is Bezos’s principle of focusing on long-term constants.6 For instance, users universally appreciate fast, responsive software. They value web apps that feel native, with background synchronization and instant interactions, that work well on all their devices. At worst, they might not consciously notice; at best (in web-apps like Notion, Miro, Gmail, and Google Docs), performance becomes a key differentiator that customers explicitly value.
6 Bezos frequently said of Amazon’s strategy: When you have something that you know is true, even over the long term, you can afford to put a lot of energy into it. His examples include customers wanting lower prices, faster shipping, and fast, fair customer service.
Not all features enjoy universal appeal. Rather than attempting precise numerical breakdowns of potential user interest, identify the features where essentially all customers will either value it, or at least enjoy it. Sometimes this certainty exists because is mandatory, even if mundane. Enterprise requirements like SOC 2 compliance aren’t exciting, but they’re undeniably valuable when selling to the Enterprise. This certainty compensates for the lack of differentiation.
The caveat: your most innovative, differentiated ideas rarely fall into this “absolutely certain” category. While certainties are valuable, they’re unlikely to be your strategic differentiators. This tension is natural—great products require both reliable improvements and innovative leaps of faith.


Quick discovery
I’ve been a long-time advocate of systematically interviewing potential customers to validate ideas before you start building. Still, I have to admit that this falls into the “confidence” trap. You never really know until you build. (You can, however, invalidate before you build, saving you months if not years of wasted time; therefore this is still the right place to begin.)
The typical solution is to build an SLC (my upgrade to an MVP), i.e. a completed but simple product that generates real feedback. Experience, rather than prediction. For existing products, that means maintaining a balanced portfolio between guaranteed wins and innovative bets, applying different validation methods to each.
For example, consider implementing “dummy features”—buttons that, when clicked, reveal: “This feature isn’t built yet. Tell us how you’d use it.” This simple test provides real signals: a count of interested users and potential interview candidates who’ve demonstrated interest through action rather than words. They can provide insights before you build the feature.
This approach generates 100x better signal than surveys asking hypothetical questions. People easily say “yes” to survey questions about future usage, but taking an action—even clicking a button—requires genuine interest. Observed behavior beats stated intentions every time.
Customer impact
Replace confidence with impact. I define impact in two distinct ways:
- Majority rule
- When the majority of users regularly use a feature, it’s undeniably important—likely a key reason people adopt and retain your software.
- Passionate advocates
- Features that create passionate advocates among a smaller subset of users. These “magnificent delighters” won’t appeal universally, but they inspire deep loyalty in specific segments. Like a piece of music that’s someone’s all-time favorite (while others merely acknowledge it’s objectively good).
These are what determine purchase decisions. Your product rarely satisfies every customer need perfectly, but when users absolutely love certain aspects, they’ll tolerate shortcomings elsewhere. We see this with beautifully designed software—users accept missing functionality or limited platform support because the design experience itself is so compelling. There are many other reasons for a customer to love you despite your failings.
These “killer delighters” don’t require universal appeal. If 15% of customers identify a feature as a primary reason for purchasing or remaining with your product, that’s significant. When 15% feel that strongly, many more likely appreciate it, even if less intensely.
I quantify impact with this definition: A high-impact feature either (1) is regularly used by at least 51% of customers, or (2) is cited by at least 15% of customers as among their top three reasons for choosing or retaining your product.
This sets a high bar, but innovative, risky features demand a high bar. If you’re undertaking projects that might exceed timelines or have uncertain outcomes, the potential reward must justify that risk.
Invest in leverage
There are some aspects of the business or product where small, incremental changes yield large results. It sounds too good to be true, but there are mathematical or structural areas where it is almost always true.
Maximize optionality
If we don’t know how the future will unfold, we can make choices that maximize the options we have when we get there. More than flexibility, more than avoiding lock-in, building systems that are almost always ready to handle anything that arises.
Some examples:
- Keeping costs low enables all kinds of pricing and packaging while still being profitable, allowing for testing today and resilience in future.
- Selecting well-established, actively-development cross-platform libraries and frameworks for building user interfaces, so you’re able to handle any evolution in platforms and devices.
- Plug-in systems, so that both you and your community can build things that you cannot imagine today.
- API-first architecture so that you own front-end tools, and your own back-end systems, and customer integrations, survives evolution.
- Wrappers around vendor services, so that you can swap out vendors if one becomes unstable, or too expensive, or lags behind others.
Some kinds of optionality require additional work today. For example, vendor-wrappers don’t add any value today. Those techniques are wise for mature companies where stability and predictability are more important than releasing a feature a month earlier, but might be the wrong choice for early-stage companies who must rely on their velocity to win against incumbents.
Portfolio of bets
Portfolios reduce variability at the expense of reducing maximum upside. That is, you’re unlikely to have zero wins (so your downside isn’t too bad), but wins have to make up for the losses, so even the occasional massive win isn’t as massive as it would have been. The old joke is that the best investment portfolio would have been to buy Amazon at IPO and hold forever. Sure, but if you applied that advice to some other IPOs that year, you’d have $0. A portfolio of stocks means you’ll never go to zero, but your maximum growth will be far less than best stock in the portfolio.
- Mathematical sidebar
- Why do portfolios work regardless of the underlying probability distributions?
The Central Limit Theorem makes this precise: When you draw repeated samples from any distribution, then plot each sample’s mean, the distribution of those sample means is Gaussian—a normal distribution—with a mean equal to the distribution’s mean and a variance
 of the distribution’s variance. So, total portfolio results are normally-distributed regardless of the underlying probability distribution, and we expect results near that mean, i.e. not zero, but also not near the maximum value.
of the distribution’s variance. So, total portfolio results are normally-distributed regardless of the underlying probability distribution, and we expect results near that mean, i.e. not zero, but also not near the maximum value.
Even further, the The Lindeberg—Lévy Central Limit Theorem shows that the same is true even when each sample is drawn from a different underlying probability distribution. This holds only under certain conditions (independence, finite variance, and no single variable dominates all others). Arguably these conditions fail with distributions common in startup environments, e.g. some Power Laws have infinite variance.
Portfolios work when you want solid, predictable, but they don’t work when you want outlier results. An example of the latter are venture capitalist or angels investor portfolios, where 65% lose money, and only 10% generate returns high enough to justify the risk and illiquidity. When hunting outliers, you need all-in investments, not portfolios.7
7 Mathematically, the reason for this breakage is that the underlying distribution of startup returns is a Power Law that violates the Lindeberg criteria mentioned above.
Therefore, if the goal of your prioritization exercise is to find features that will be strong differentiators in the market and strong growth drivers, a portfolio is the wrong tool. On the other hand, if you’re prioritizing a bunch of smaller things, where you want incremental but reliable results, a portfolio will get you those results. No need to argue about confidence.
Stop pretending you can quantify confidence, or even define it.
Instead, use techniques that work when the future is unpredictable.
Because it is.
But I’ve heard somebody say that if there is a doubt, there is no doubt :S
11:53 AM
Yeah, I don’t know whether that’s always true
11:57 AM
It’s a reasonable heuristic, but it’s not much of a rule.
11:58 AM
I’ve doubted lots of things that worked out, and I was >90% certain of things that didn’t work out, so I’m not sure our confidence is that accurate.
https://longform.asmartbear.com/confidence/
© 2007-2026 Jason Cohen
 @asmartbear
@asmartbear




